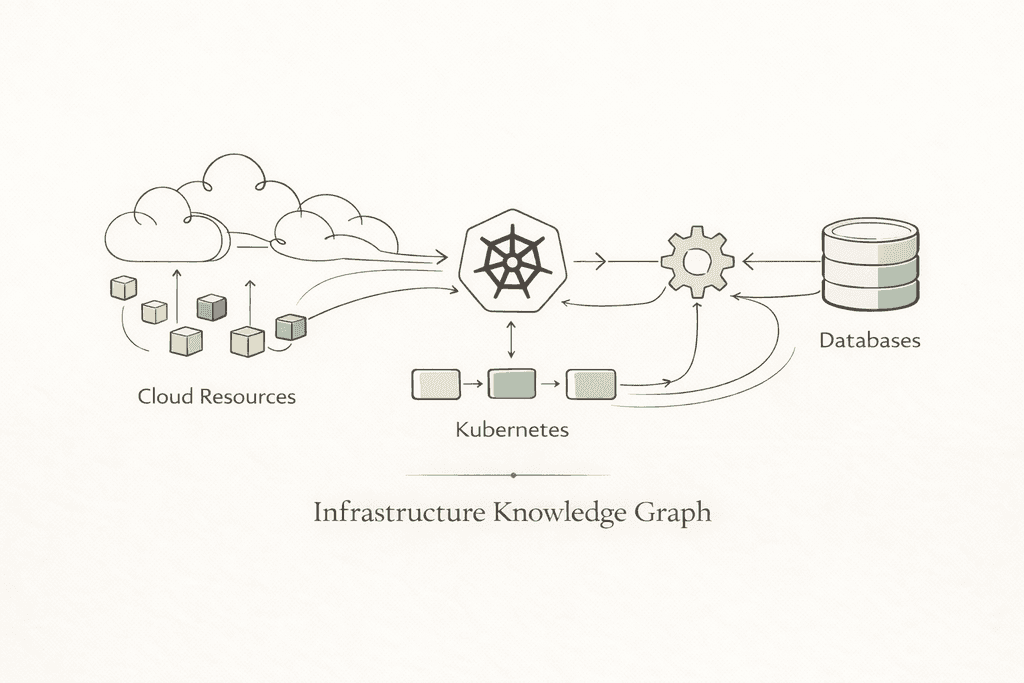
Louis Fradin is a DevRel and Backend Engineer at Anyshift, where he's helping build the AI context layer for production systems, giving teams the infrastructure graph they need so AI agents can actually understand what's running in prod.
His path to SRE started deep in the stack: four years writing Linux drivers and managing HPC infrastructure for the French Ministry of Armed Forces, followed by three and a half years at Ubisoft building and operating Kubernetes clusters at scale for game servers with Go, Temporal, Talos, or OpenTelemetry.
Today he bridges that engineering background with developer advocacy, advocating for better observability primitives and smarter AI tooling for the people keeping systems alive.

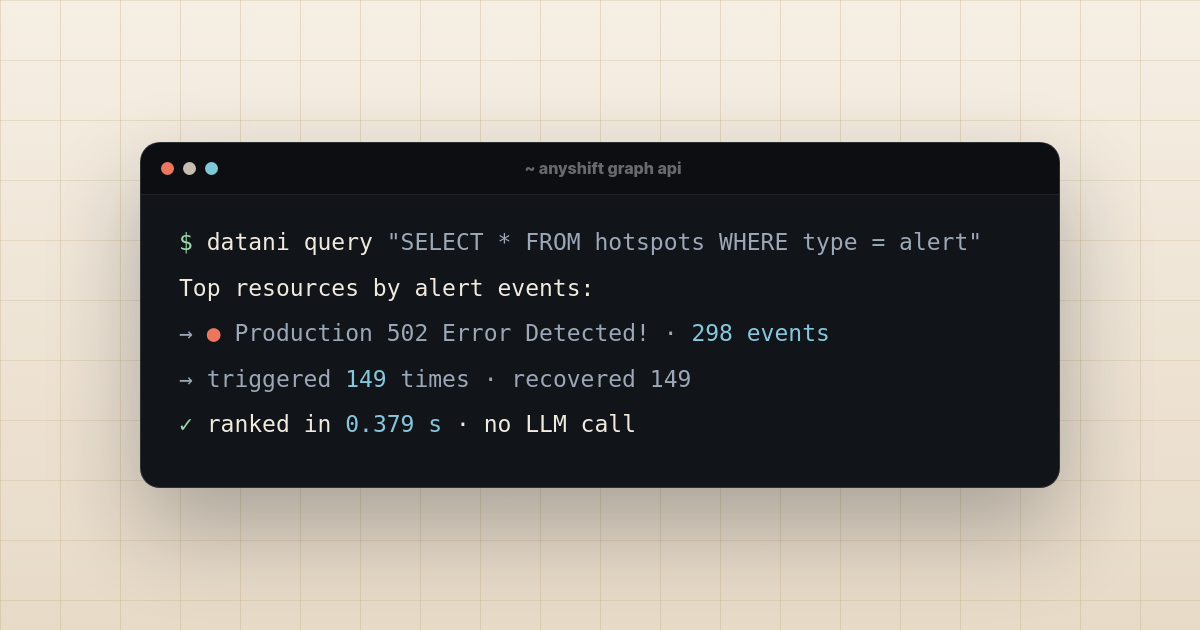




































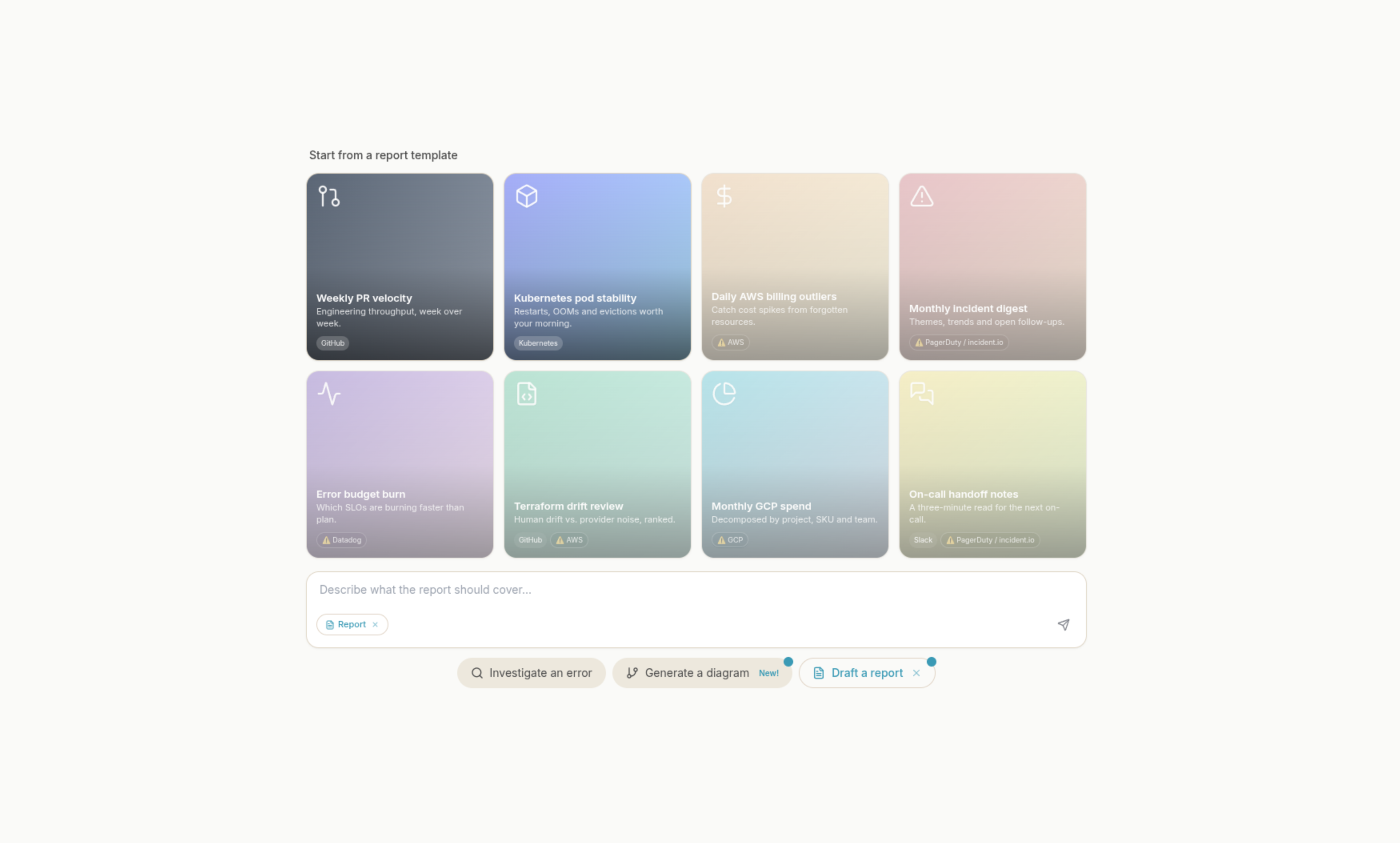

















![[Featured in Tessl] DevOps with AI: Identifying the impact zone, with Roxane Fischer](/images/blog/devops-with-ai-impact-zone.png?dpl=dpl_aZQcQPFNDWDKgoAhsrWJR5AwqRqo)