Your AI agent just made the same mistake for the third time.
An alert fires. Your AI SRE agent spins up, queries the monitoring stack, pulls logs, traces dependencies. Fifteen minutes later, it delivers a root cause analysis. Not bad. Except it spent the first three minutes querying a metric that doesn't exist under that name in this environment. And it didn't begin by checking the database connection patterns that a human SRE would validate immediately, because they've seen this exact failure mode before.
Next week, same type of incident. Same agent. Same three wasted minutes. Same missed pattern.
The problem isn't intelligence. The problem is memory. Large language models don't carry context between runs. Every investigation starts from a blank slate, and institutional knowledge, the kind that makes a senior SRE invaluable, never accumulates.
Why Fine-Tuning or RAG Isn't the Answer
The obvious fix is fine-tuning: train the model on your data so it "knows" your infrastructure. In practice, this is expensive, slow, and fragile. Models forget old knowledge when you teach them new things (catastrophic forgetting), and you need labeled datasets that most teams don't have. Fine-tuning also requires a large number of rollouts to generalize, while LLMs are remarkably sample-efficient: they can generalize from just a few examples when the right context is provided. This is exactly the intuition behind ACE. Rather than training on thousands of examples, you build and evolve playbooks that let agents leverage few-shot learning at inference time.
Retrieval-augmented approaches (RAG) help, but they treat context as a static document. You write a runbook once and hope it stays relevant. There's no mechanism for the context itself to evolve based on what actually works in production.
This is the gap that ACE (Agentic Context Engineering) fills. Developed by researchers at Stanford and SambaNova Systems and accepted at ICLR 2026, ACE treats agent contexts not as fixed prompts but as living documents that improve through use. Instead of training the model, you evolve the context around it.
Two problems motivated the work. Brevity bias: when asked to rewrite their own context, models tend to compress and lose detail with each iteration. Context collapse: without structure, accumulated knowledge drifts into vague generalities that sound helpful but aren't actionable. ACE addresses both through a structured, incremental approach to context evolution.
The Learning Loop
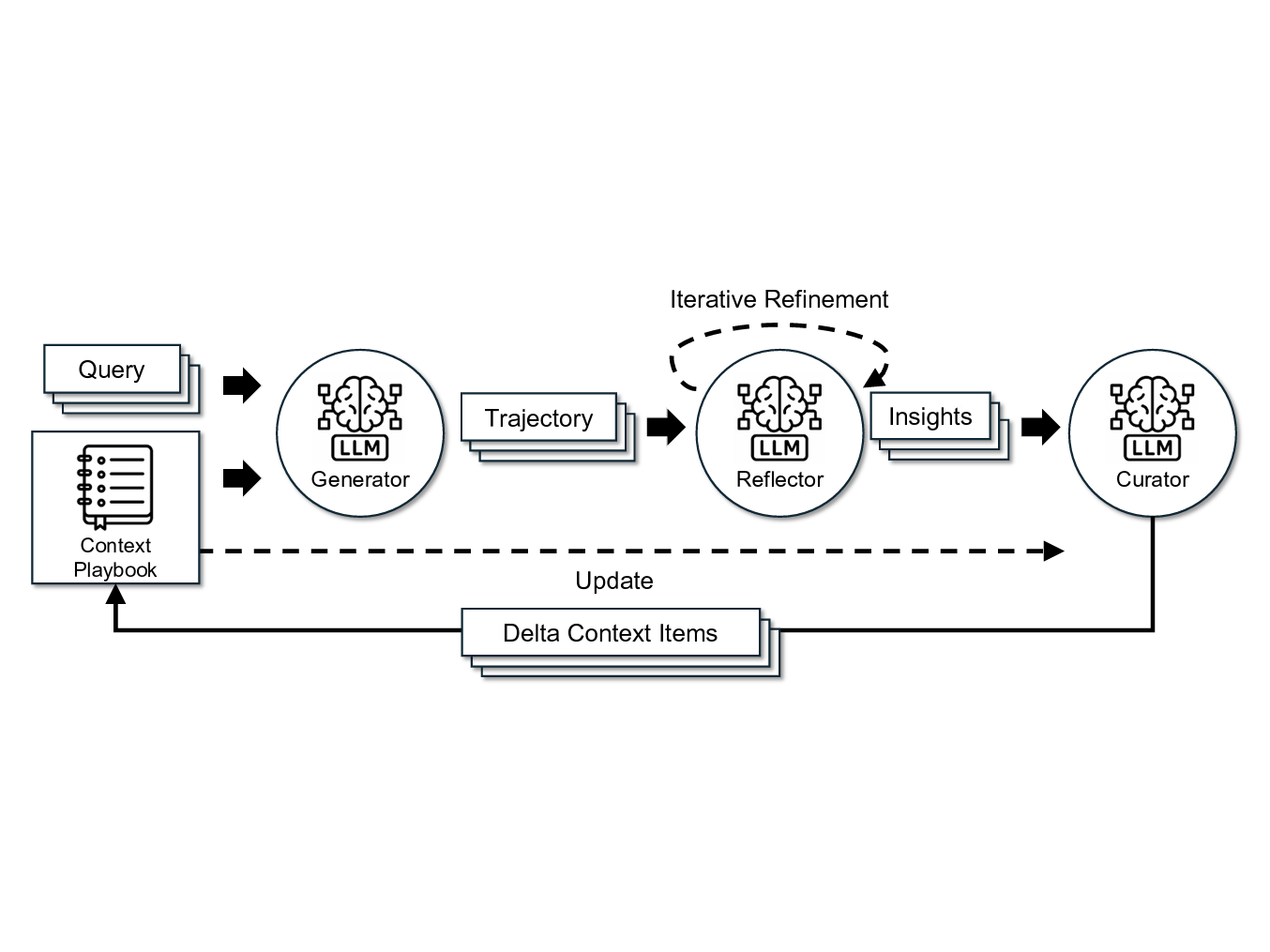
ACE works through three phases that repeat after each agent run:

The agent runs against real incidents, using whatever playbook currently exists. After the run completes, a Reflector analyzes what happened: what tools were used, what information was found, what was missed, what worked well. Finally, a Curator takes those reflections and decides what to add, update, or remove from the playbook.
The key insight is that updates are incremental and structured. Rather than rewriting the entire context from scratch (which triggers brevity bias), the Curator makes targeted additions and edits. Each piece of knowledge is a discrete "cheatsheet" that can be individually added, modified, or pruned. This prevents context collapse by keeping knowledge organized and actionable.
Over time, the playbook becomes a distilled representation of what the agent has learned from real production experience, not what a human thought to write down in a runbook.
From Benchmarks to Production
The ACE paper demonstrated strong results on academic benchmarks: +10.6% on agentic tasks, +8.6% on domain-specific tasks, with 86.9% lower adaptation latency compared to fine-tuning. But benchmarks are controlled environments. We wanted to know: does this hold up when your infrastructure is messy, your naming conventions are inconsistent, and every client's environment is different?
At Anyshift, we build Annie, an AI SRE that investigates incidents, analyzes infrastructure, and responds to alerts across our clients' production environments. We implemented ACE in October 2025, just a few weeks after the paper was made public, because the problem it solves was one we were already wrestling with.
The first thing that became clear in production is that every client's environment is different. One client uses canary releases that look like pods randomly spawning and dying if you don't know the deployment pattern. Without that context, the agent flags it as instability. With a playbook that has learned the client's deployment strategy, it recognizes the pattern and moves on. Escalation paths, on-call structures, which dashboards matter for which services: all of this is specific to each client's infrastructure. ACE naturally captures these idiosyncrasies. After a few investigation runs in a new environment, the agent's playbook contains the client-specific baselines and patterns that would take a human SRE weeks to internalize.
It was tricky to evaluate whether the accumulated knowledge was actually helping. We developed internal evaluation methods that compare agent performance with and without ACE-evolved playbooks, measuring multiple quality dimensions to determine whether the playbook is genuinely improving investigations or just adding noise.
What Agents Actually Learn
The most interesting part isn't the framework itself. It's what shows up in the playbooks after a few weeks of production use.
Naming conventions and service maps. Agents quickly learn that a specific client names their Redis clusters cache-{region}-{tier} rather than the more common redis-{env}-{n} pattern. This sounds trivial, but it's the difference between an agent immediately finding the right metrics and spending minutes trying variations.
Business behavior baselines. One client's payment service normally throws 200 errors per hour during batch processing windows. Without ACE, the agent flags this as a problem every time. With ACE, it learns that this is expected behavior and focuses on actual anomalies.
Investigation strategies. For certain types of alerts, the agent learns which tools to check first and which are likely dead ends. "For this client's API latency alerts, always check the database connection pool before looking at upstream dependencies" is exactly the kind of knowledge that makes a senior SRE faster than a junior one.
The Unexpected Side Effect: ACE as a Customer Success Accelerator

This one caught us off guard. Traditionally, onboarding an AI tool into a client's environment requires significant customer success effort. A CSM gathers feedback, translates corrections into documentation, updates runbooks, and makes sure the system reflects how the client actually operates. It's manual, slow, and scales linearly with the number of clients.
ACE fundamentally changes this dynamic. When a client sees an RCA report and says "you're looking at the wrong upstream, that service was migrated last quarter," that correction doesn't go into a ticket queue. It flows through the Reflector and Curator, and the next investigation already knows. The agent onboards itself into each client's environment through the natural course of doing its job.
What we didn't expect is how much this changes client behavior. When people see the agent visibly improving from their feedback, they start volunteering information they wouldn't have thought to document otherwise. They point out naming conventions, explain why certain error patterns are expected, and share the kind of tribal knowledge that usually lives in one person's head. ACE turns every client interaction into a training signal, without anyone having to fill out a form or write a runbook.
The result is that a significant chunk of what would traditionally be CSM effort, the painstaking work of translating client-specific knowledge into system configuration, happens organically. Annie learns the way a new hire learns: by doing the job, making mistakes, getting corrected, and not making the same mistake twice.
Results


Internal evaluations showed statistically significant improvements across three quality dimensions: agents with ACE-evolved playbooks select the right investigative tools faster, produce fewer false leads and misidentifications, and deliver more complete impact assessments.
The 30% reduction in root cause analysis time is meaningful, but the qualitative improvement matters more. It's not just that agents are faster. It's that they make fewer mistakes of the kind that erode trust: querying nonexistent metrics, missing obvious connections, flagging normal behavior as anomalous. These are precisely the mistakes that disappear when an agent has institutional memory.
What's Next
ACE in production has opened several research questions we're exploring with the Stanford team.
How do you benchmark long-term memory for AI agents? Current benchmarks evaluate narrow, short-horizon capabilities, but production agents need to retain and recall domain-specific knowledge over weeks and months of operation. The ACE team is working on evaluation frameworks that capture what it actually means for an agent to have durable, useful memory.
On our side, the next challenge is scaling context evolution to enterprise clients with intricate team structures. When an organization has dozens of teams, each with their own services, conventions, and access boundaries, memory can't be a single flat playbook. Some knowledge should be shared across teams, some should be restricted, and some should only be visible to specific roles. Building the right memory meshing and isolation model for these environments is among the problems we're most excited to take on next.
These are the kinds of questions that only emerge when a research framework meets production reality. That's what makes this collaboration valuable: the ACE team brings the theoretical foundations, and production deployment generates the edge cases and extensions that push the framework forward.
If you're running AI agents in production and dealing with the "blank slate" problem, the ACE paper is worth reading. And if you want to see what an AI SRE with institutional memory looks like in practice, come talk to us.
ACE (Agentic Context Engineering) was developed by researchers at Stanford University and SambaNova Systems. The paper was accepted at ICLR 2026. Anyshift has been running ACE in production since October 2025.
Co-authored with the ACE team (Stanford / Berkeley / SambaNova).
Continue reading:
- Why AI-SRE Needs Topology, Not Just Telemetry — Why telemetry alone isn't enough for AI incident resolution.
- Top 10 AI SRE Tools in 2026 — How leading AI SRE platforms compare on architecture, RCA, and change awareness.
- Building a Temporal Infrastructure Knowledge Graph — The graph that powers Annie's institutional memory.
